Writing multithreaded programs is challenging task both because of programming and debugging. Let’s see what traps await for lone rider entering Parallel Universe.
More is less
Psychological research shows that people becomes unhappy when they are overloaded by multiple possibilities. Well if this is true, then analyzing concurrent program could cause serious nervous breakdown of unprepared minds. Number of execution possibilities grows exponentially because of thread scheduler non-determinism. Let’s assume that we operate in sequential consistent model (e.g. execution on single core) and we have only two threads that are executing instructions:
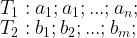
Number of possible interleaved executions is equal to number of permutations with repetition

Assuming that m = n

which means exponential growth of possibilties with number of instructions.
Even if there are only 2 threads with 3 instructions per thread, there is 20 possible cases to analyze (enumerate it by yourself if you have too much time). This is enough to make your life miserable, but real world programs are much more complicated than this. And it implies that your mind is physically incapable to analyze so many possibilities.
To ensure correctness we have to use locks, which also reduces number of possible execution scenarios (because now several instructions are atomic and could be viewed as single instruction). It also introduces new opportunities to break your program (like deadlocks or priority inversions) and experience performance drops.
Your friend becomes your enemy
In single threaded programming compiler guarantee that even after optimizations your program will have same effect as before optimizations. This is no longer the case in multithreaded programming. Compiler is not able to analyze all instructions interleaves when multiple threads are present, but it will still optimize program as single threaded application. It means that now you are fighting against compiler to suppress certain optimizations.
Simplest optimization that can breaks things is dead code elimination. Consider following code:
#include <cstdio>
#include <pthread.h>
#include <unistd.h>
bool flag = false;
void* thread_func(void*)
{
while(!flag); //spin
pthread_exit(0);
}
int main()
{
pthread_t t;
pthread_create(&t, 0, thread_func, 0);
sleep(1);
flag = true;
pthread_join(t, 0);
return 0;
}
New thread waits for flag to become true and exits. After that, main thread terminates. But with optimization -O3 program goes into infinite execution. What happened? Disassembly for thread_func is following:
_Z11thread_funcPv() _Z11thread_funcPv+20: jmp 0x400744 <_Z11thread_funcPv+20>
It’s exactly an infinite loop. Compiler made an assumption that program is single-threaded, so flag=true will never happen during thread_func execution. Therefore code can be transformed into endless loop (notice that even call to pthread_exit has been wiped out as a dead code).
Another optimization that can be deadly is variable store/reads reordering. Compiler may reorganize reads and writes of non-dependent variables to squeeze more performance. Of course assumption about single threaded execution still holds, so compiler will don’t bother about dependencies between multiple threads. This will probably result in erroneous execution, if such dependencies exists.
In C/C++ both optimizations can be relatively easily found by looking into disassembly listings and fight back by proper use of volatile keyword (e.g. in previous program declaring flag as volatile bool will fix it). But if you think you have defeated final boss you are unfortunately wrong…
The Grey Eminence of all optimizations
Processor. He has last word when and in what order variables will be stored in memory. Rules are similar as with compiler – if program executes on single core, optimization performed by CPU will not affect results of execution (except performance). But when program is executed on multiple cores and each core can reorder instruction in its pipeline you can watch how things break.
To fight back processor reordering first you have to know when reordering may take place. Rules of memory operations ordering are written in processor specification. An Intel has relatively strong consistency model – which means there are not too much cases when it can reorder memory operations. Specification says
Reads may be reordered with older writes to different locations but not with older writes to the same location.
It could break some algorithms like Dekker or Peterson mutual exclusion, but other programming constructs like Double Checking Locking pattern may work correctly. Other processors like Alpha are not so forgiving and almost any memory operation could be reordered (which means Double Checking Locking Pattern won’t work without explicit memory barriers).
If you already know where reordering can cause problems you can suppress it with proper Memory Barrier instruction. In the contrast with compiler optimizations – you are not able to see if processor runtime optimization took place – you can only see its effects. And fighting with invisible opponent can be pretty damn hard.
In next parts of Adventures in Parallel Universe we will explore some concepts presented here more deeply along with the new stuff.

2 Comments